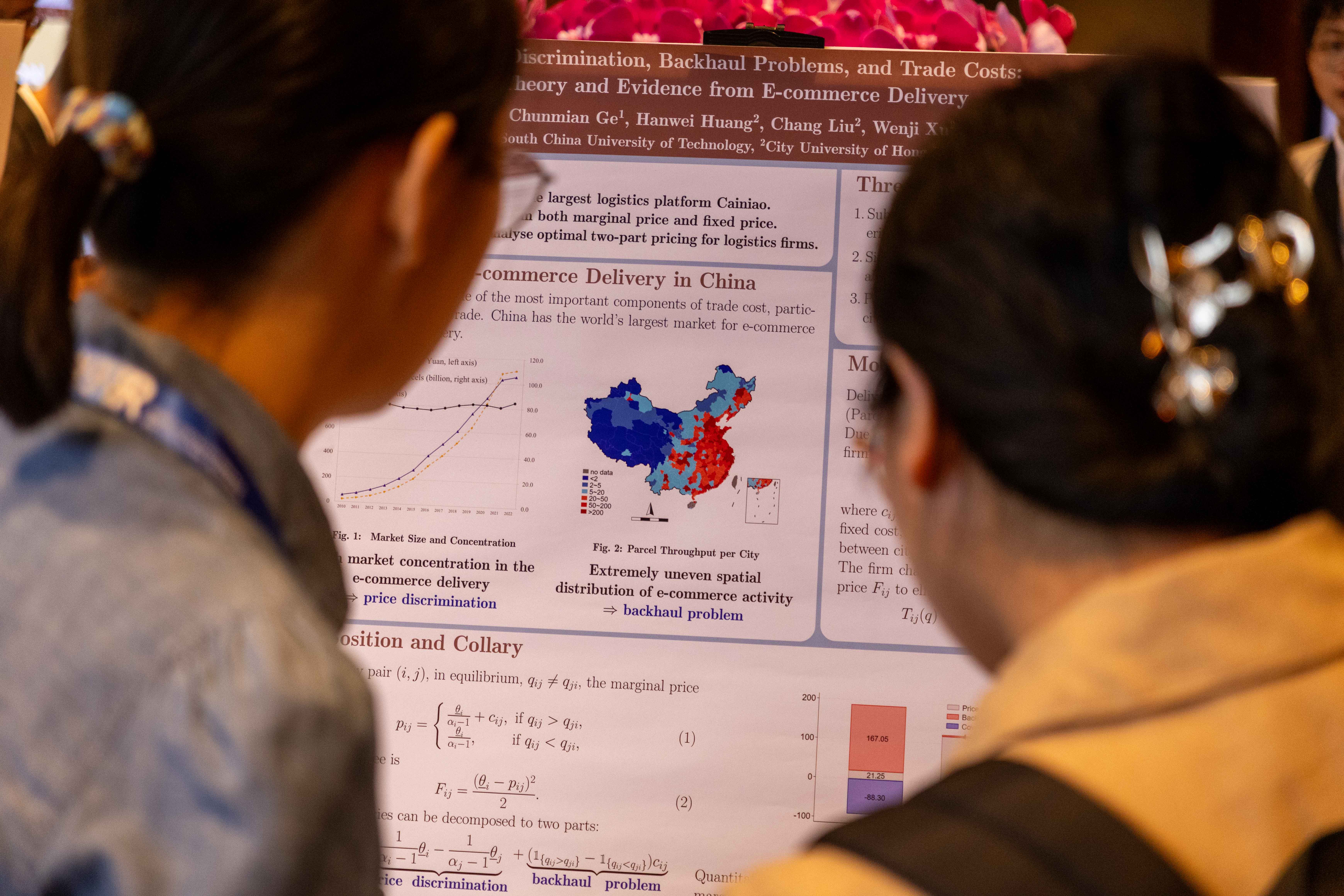
The authors examine whether large language models (LLMs) can extract contextualized representation of Chinese public news articles to predict stock returns. Based on representativeness and influences, the authors consider seven LLMs: BERT, RoBERTa, FinBERT, Baichuan, ChatGLM, InternLM, and their ensemble model. The authors show that news tones and return forecasts extracted by LLMs from Chinese news significantly predict future returns. The value-weighted long-minus-short portfolios yield annualized returns between 35% and 67%, depending on the model. Building on the return predictive power, the authors further investigate its implications for information efficiency. The authors show the assimilation speed of the LLM signals is two days, and they contain fundamental information. The signals can be especially helpful under higher frictions, when firms have less efficient information environments, more complex news, and higher retail holdings. Interestingly, heterogeneous investors load their future trades oppositely on LLM signals upon news releases. These findings suggest LLMs can be helpful in processing public news, and thus contribute to overall market efficiency.
Session Chair:
Bernard YEUNG
Emeritus Professor, National University of Singapore; Visiting Chair Professor, Southern University of Science and Technology (Shenzhen); Exco Member, Council and Senior Fellow, ABFER
Updated 17 Dec 2024
Session Format
Each session lasts for 1 hour 10 minutes (25 minutes for the author, 25 minutes for the discussant and 20 minutes for participants' Q&A). Sessions will be recorded and posted on ABFER website, except in cases where speakers or discussants request us not to.
Registration
Please register here to receive a unique Zoom link. (Notice: Videos and screenshots will be taken during each session for the purpose of marketing, publicity purposes in print, electronic and social media)